Machine Learning System Design Interview Extension— Introduction

I’ve recently picked up the Machine Learning System Design Interview book for Christmas, which is undoubtedly one of the most insightful and engaging books I’ve read in 2023.
I had a lot of fun reading the book, and I began by designing the system before starting each chapter to see how the system could have otherwise been designed. This is like practising the philosophy of “design it twice”, a practice I have picked up from another great book “A Philosophy of Software Design”.
While working through the book, I found a few components in my design that I would consider or extend in my personal design, which prompted me to start this series to extend the following chapters:
In each part of the series corresponding to a chapter in the book, will add my thoughts on the following topics:
Starting with the Heuristic Models
Personally, I always try to build a heuristic system whenever possible before developing an ML solution (a heuristic solution is required as part of the RFC in my team).
The following list are reasons why I believe a heuristic model should be pursued wherever possible:
- Data collection: ML system often requires training data that may not be available in the initial phase of a project; shipping a heuristic model will enable the data collection for model training.
- Establishment of a benchmark: The heuristic model can be used to calculate the ML model's return on investment (ROI), which can be used for performance review and as input for whether a model is worth maintaining in the future.
- A reliable fallback: Due to the higher complexity and greater failure points (e.g. failing data pipeline or corrupted serving inputs), having a reliable fallback can ease the pressure during production downtime and minimise user impact.
- Low maintenance effort: In my experience, developing and shipping an ML system is the easy part of the ML lifecycle. Responding to changing requirements, maintaining the data pipeline and explaining the model's behaviour to stakeholders are costs that can often exceed the return an ML model provides over the heuristic model.
ML Model Testing
This is a relatively new area for ML models, but I strongly believe and have benefited from writing behavioural tests. If you are unfamiliar with behavioural tests, I’ve written a short introduction with examples.
A behavioural test for the ML model provides transparency and confidence in the behaviour of a black box system and safeguards against unexpected behaviour.
Let’s say we have a pricing model for a ride-hailing service; while we may not know how the model predicts a price, we should always expect that, on average, the longer the trip distance, the greater the price. This is an example of a directional expectation test; if this condition does not hold, there is something wrong with the model.
For each system, I will provide examples of the test and details of how I would construct the tests.
Model Update and Experimentation
In practice, we rarely ship the model, and the model performs optimally. Experimentation and optimisation are the norm and where an ML team can continue to provide value.
In this section, I will share how we can design experiments and the potential extension to the system required to support the experimentation.
An experiment engine is usually required to support experimentation; the experiment engine should provide the following functionality:
- An interface for users to create experiment configurations.
- A randomisation algorithm to assign the request to the treatments.
- Provide the interface to retrieve the corresponding experiment and treatment for a query.
- Log the result of the assignment for later analysis

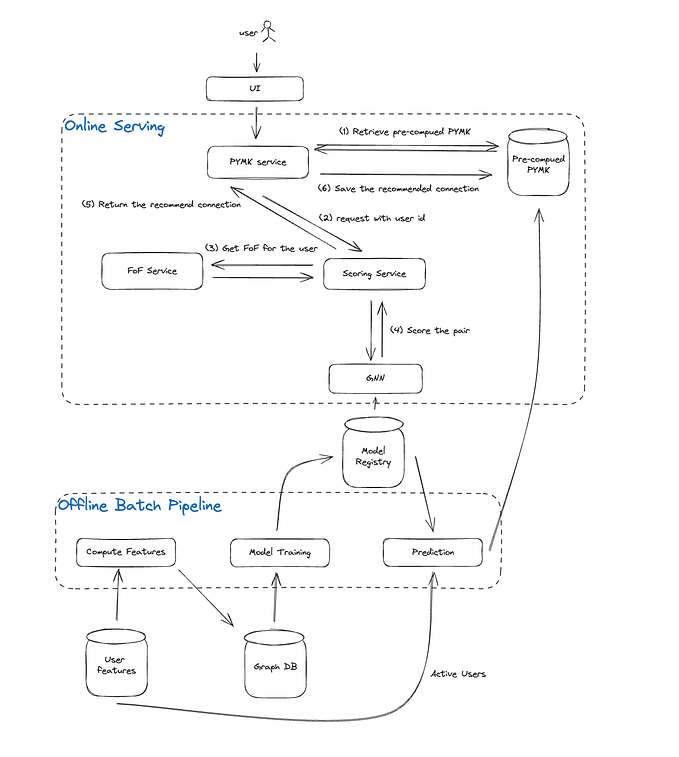
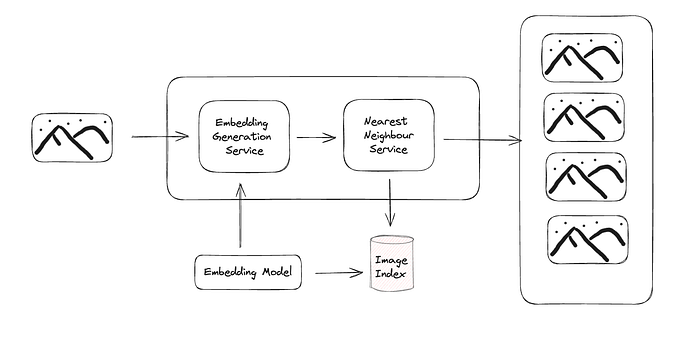
Let’s start with the first chapter on designing a visual search system without further ado!